周六日两天的北京大雨下个不停,无法出门。正好听说深度学习领域的大牛 Andrew Ng 的新创业项目竟然是与 Coursera 合作的一个关于深度学习的系列课程,果断报名参加。花了两天的时间看完了第 1 门课程 Neural Networks and Deep Learning 的视频,也做完了相关作业。相较其它课程不同,也是其中比较有意思的一点是,每一周的课程结束都有一段 Andrew 采访当今人工智能领域权威人士的视频。通过采访视频,也能够了解到一些人工智能技术的发展历史,还是相当不错的。
1. 什么是神经网络
话不多说,上图为敬。一个典型的神经网络结构图如下所示:
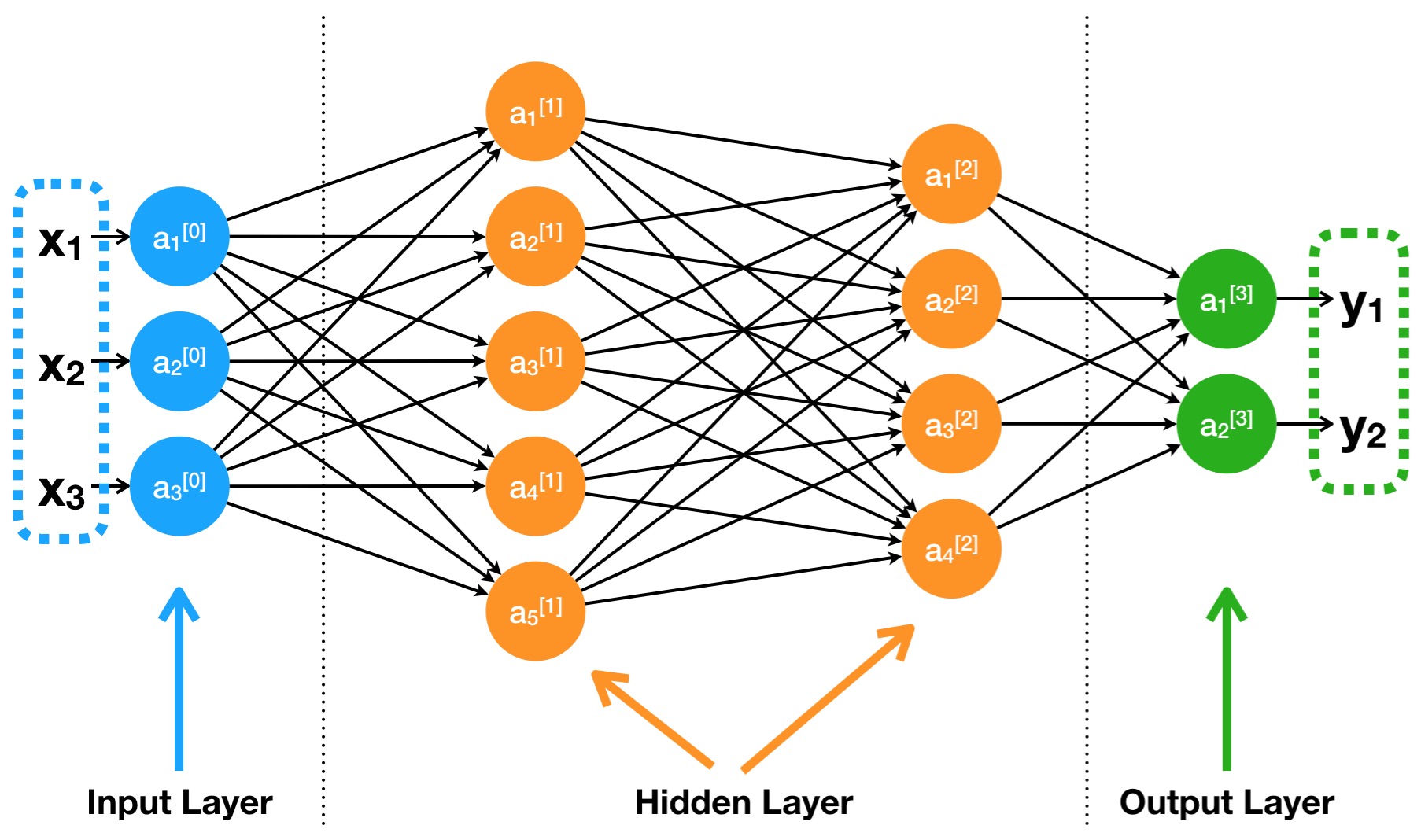
层:神经网络是一个分层 (Layer) 结构,一般的神经网络都由输入层 (Input Layer)、隐藏层 (Hidden Layer)、输出层 (Output Layer)所组成。其中隐藏层的数量根据所构建的神经网络的复杂程度可以从零达到几百。
节点:神经网络中的每一层都是由若干个节点 (Node) 所组成。我们可以把节点理解为对数据处理的单元,每个节点的作用就是接收所有传入的数值,经过计算处理后输出一个数值。同一层的所有节点的输出值组合起来就是一个 $N \times 1$ 维的向量,$N$ 为该层中节点的个数。特别的是,第 0 层(输入层)中的每个节点对输入的数值不做任何处理直接输出,也可以把第 0 层当作数据本身。比如最常见的图像数据,如果彩色图像数据像素为 $64 \times 64$,考虑到其中的三个颜色通道,那么向量化输入的数据应该是长度为 $64 \times 64 \times 3 = 12288$ 的列向量。
连接:同一层之间的节点没有连接,非相邻层之间的节点也没有连接,相邻层之间的任意两个节点之间都有连接。通过这种连接使得一层中的节点存储的值传递到下一层中的各个节点。需要注意的是,数据在从一层传递到下一层的过程中是经过了加权的。
虽然从图中看起来,神经网络很复杂,但是如果把整个神经网络想象成一个黑盒子,它的唯一作用就是对不同的输入变量,返回相应的输出值,这就是函数的功能。神经网络本质上是一个复杂的函数,对输入变量返回输出结果。
2. 神经网络中的前向传播
所谓的前向传播 (Forward propagation),指的是数据从输入层开始,依次经过隐藏层(如果有)最终到达输出层的过程。其中,数据每经过一层传播,其节点输出的值所代表的信息层次就越高阶和概括。举例来说,对于一个识别图像是否包含人脸的神经网络来说,输入数据组成的向量中每一个元素表示的只是图像的灰度值信息。经过一层处理之后,可能第二层中的每个节点输出的值代表的是各种不同的边缘信息。第三层输出值代表的是边缘信息组合成的更高阶部位信息,比如鼻子、眼睛等等。最后输出层代表的就是系统对输入数据的判断结果,即是否是一张人脸。这里需要指出的是,节点中输出的值是通过与其相连的前一层中所有的节点输出值的加权求和处理后的结果。这也是接下来需要着重介绍的。
2.1 节点中的细节
如果深入到神经网络中的其中一个节点(以上图中的 $a_1^{[1]}$ 为例),我们会得到如下的一张结构图:
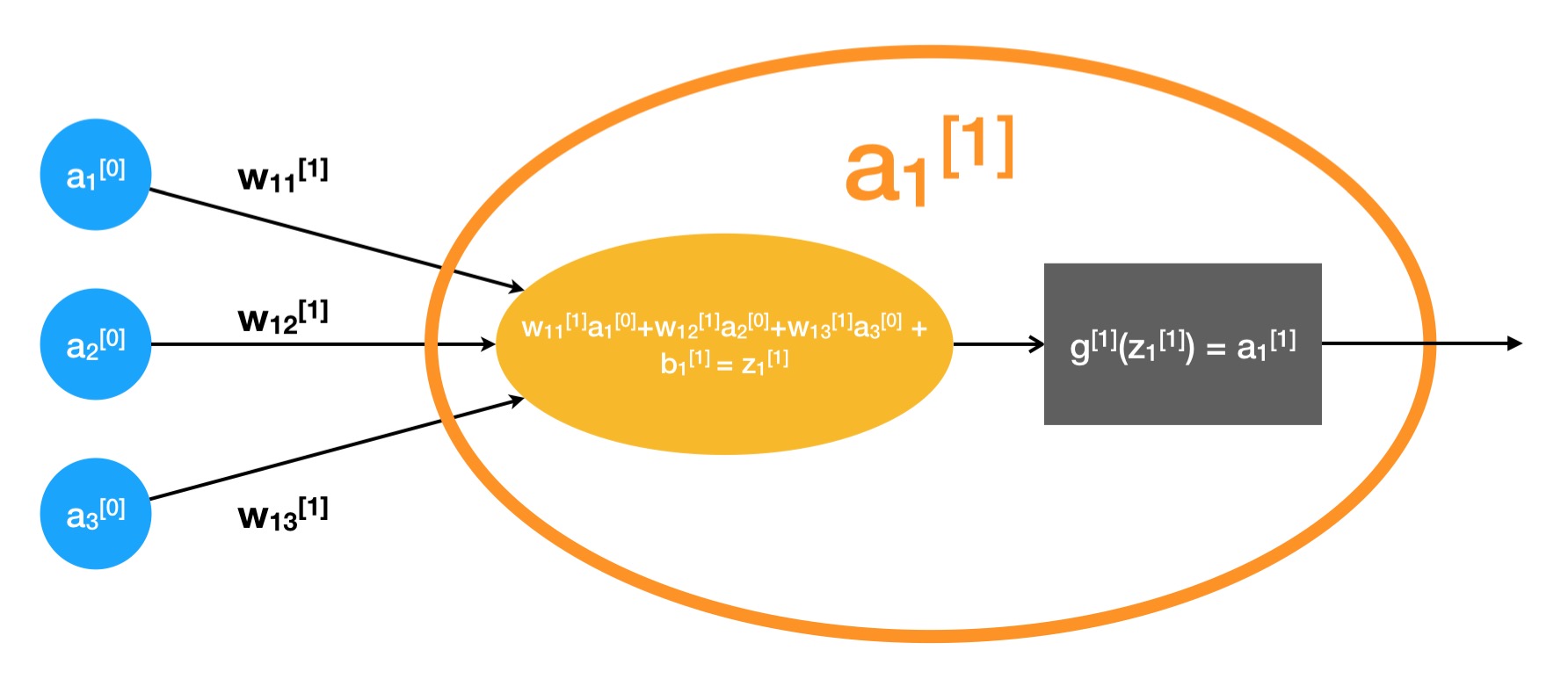
从图中可以明显的观察到,一个节点其实是由两部分组成:一个是加权求和部分,一个是对求和结果进行处理的部分,我们称这部分为激活函数。下面分别介绍。
2.1.1 加权求和
就上图来说,我们可以把前一层中每个节点 $\left( a_1^{[0]}, a_2^{[0]}, a_3^{[0]} \right)$ 指向本节点 $\left(a_1^{[1]}\right)$ 的箭头理解为上层节点的输出值对本节点的影响。
不同的节点输出值对本节点的影响程度不同,即具有不同的权值。我们用带上下标的字母 $w$ 来表示这个权值,$w_{ij}^{[l]}$ 表示的是第 $l-1$ 层中第 $j$ 个节点的输出值对第 $l$ 层中第 $i$ 个节点的影响程度。图中的字母标记与该准则一致。
仔细观察图中加权求和公式会发现其中含有一个常数项 $b_1^{[1]}$,我们可以把该常数项理解为节点 $a_1^{[1]}$ 对输入值敏感程度的一个纠正。推广开来,我们用 $b_i^{[l]}$ 表示第 $l$ 层中第 $i$ 个节点中的常数偏置,英文中称作 bias。
我们用 $z_i^{[l]}$ 表示第 $l$ 层中第 $i$ 个节点中的加权求和结果。求和结果之后传给激活函数,经过激活函数的处理输出。
2.1.2 激活函数
激活函数是节点之所以存在的根本原因。神经网络之所以叫神经网络,就在于其模拟了生物中的神经系统。在神经系统中的每个神经元都通过轴突与树突与很多其它的神经元相连,神经元接收一些神经元发出的电信号,同时发出一定的电信号给其它神经元。即使不懂生物学中的相关知识,凭借常识我们也能推断出,首先神经元发出的电信号不可能无限大,其次神经元也不能无脑转发所有接收到的电信号信息量,否则其存在的意义就没有了。
具体到神经网络中节点的激活函数也是一样,激活函数如果不存在或者只是一个简单的线性函数,那么节点存在的意义也就没有了。从数学上也能证明这一点,如果节点的激活函数是线性函数,那么其与前一层所有的加权连接都能直接增加另一个权重直接与下一层的各节点相连。
所以,神经网络中的激活函数必须存在,并且一定不能是线性函数。一般情况下我们以 $g()$ 来表示激活函数,根据目的的不同,激活函数可以选取下边几种具体函数形式中的一种:
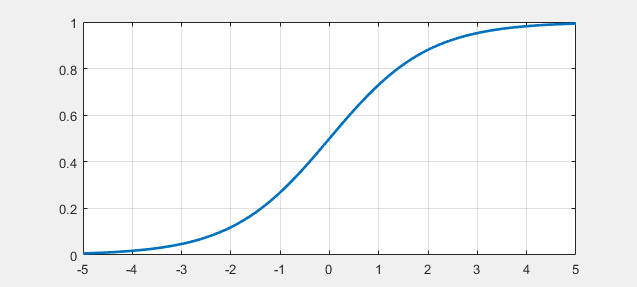
- sigmoid 函数 数学表达式以及函数曲线如下:
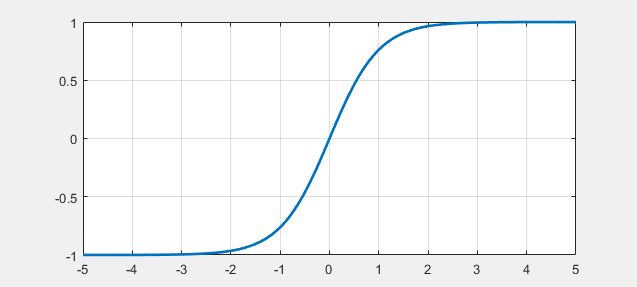
- tanh 函数 数学表达式以及函数曲线如下:
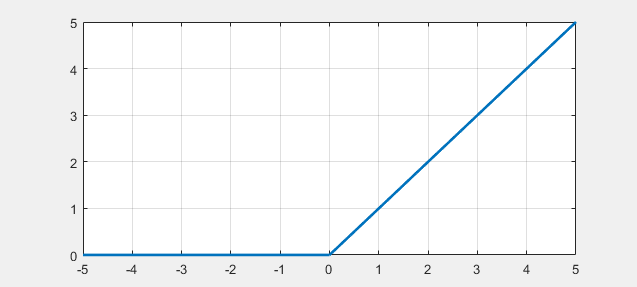
- ReLU 函数 数学表达式以及函数曲线如下:
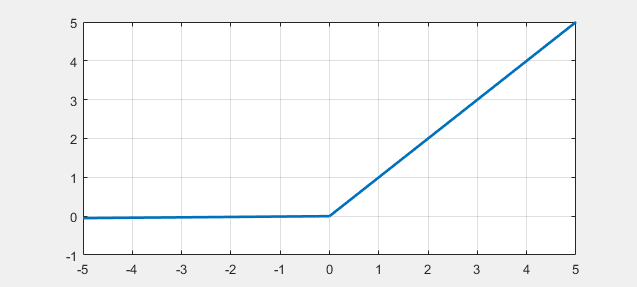
- Leaky ReLU 函数 数学表达式以及函数曲线如下:
2.2 向量化表示
还是以节点 $a_1^{[1]}$ 为例,学过线性代数的我们很容易可以把 $z_1^{[1]}$ 的计算表达式写成:
同理,
以此类推,如果我们做如下定义:
自然就得到:
以及,第一层节点的输出值的向量化:
其中 $g^{[1]}$ 表示第1层各节点中的激活函数通用表达。
我们可以很容易地把上边的推导过程一般化:
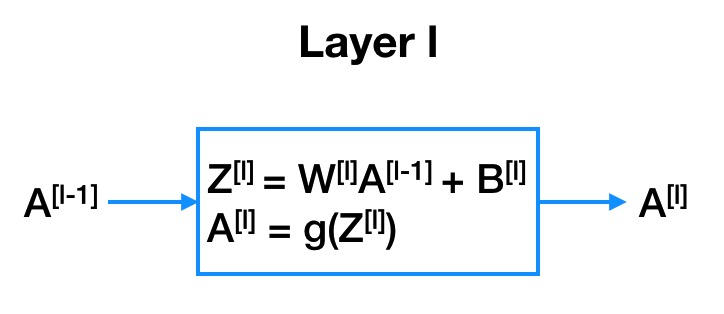
若第 $l$ 层中节点数为 $m$,第 $l-1$ 层中节点数为 $n$ 。那么,$Z^{[l]}$, $B^{[l]}$, $A^{[l]}$, 的维度为 $m\times 1$,$A^{[l-1]}$ 的维度为 $n\times 1$,$W^{[l]}$ 的维度为 $m \times n$ 。
2.3 前向传播的图形化表示
3. 神经网络中的反向传播
经过上一节的分析,我们可以得出这样的结论,所谓的前向层传播说的就是,输入数据在神经网络的各层的各个节点之间传播的过程,最终得到结果输出出去。在这个过程中,神经网络中的各个节点的参数,即 $W^{[l]}$、$B^{[l]}$ 是已知的。
但是在实际的应用中,我们往往是知道了输入数据以及输出结果(针对监督学习来说,输出结果通畅指分类标签),想要求取一个结构设计好的神经网络的参数。这其实就是一个函数参数拟合问题。针对函数的参数拟合问题,数学上已经有了很成熟的通用方案。通常来说,对于比较简单的函数形式,数据量也不是很大的情况,可以尝试用最小二乘法来拟合求取函数的参数。但是对于复杂的函数形式,同时数据量非常巨大的情况,最小二乘法就不是一个很明智的选择,一般都会选择某种迭代求解的方案一步步逼近最优参数。其中用的最多,通常来说也是最有效的方法是梯度下降法。
在神经网络参数确定的问题中,就采用的是梯度下降法。
3.1 为什么可以用梯度下降法
梯度下降法是一个用来求取函数极值点的方法。简单来说,能够用梯度下降法来求取神经网络中各节点的参数的理由是,我们能够比较容易的构造出一个关于参数 $(W^{[l]}$, $B^{[l]})$ 的函数 $\mathcal{J}$ (神经网络的参数在这个函数中属于变量的角色),使得该函数在极值点处对应的参数 $(W^{[l]}$, $B^{[l]})$ 取值正好是对所有样本数据的最佳拟合值。一般我们称构造的函数为代价函数 (cost function),或损失函数 (loss function)。
具体的说,如果我们把神经网络的函数形式表达为:
其中 $L$ 表示神经网络的层数,对于每一个样本 $X^{(m)}$ 都有一个对应的实际观测值 $Y^{(m)}$ 以及通过神经网络的计算结果 $\hat{Y}^{(m)}$。假设我们有 $M$ 个样本,我们可以取代价函数的形式如下:
因为我们知道,平方和函数是一个只有一个极小值点的函数,在最小值点处,对应了神经网络的预测结果大部分都要与观测结果一致。也就是说,在极小值点处,神经网络的参数是最优的。当然实际应用中可以选取的代价函数具体形式有很多种,并不局限于平方和这一种方式。
不管采用哪种形式的代价函数,我们的最终目的是通过梯度下降法来获得代价函数的极值点对应的参数值。
梯度下降法的迭代形式为:
下标 $(i)$ 表示第 $(i)$ 次迭代。$\alpha$ 叫做迭代步长,控制了每次迭代变量改变的速度,一般会取一个较小的值。$\frac{\partial \mathcal{J}}{\partial W^{[l]}}$ 和 $\frac{\partial \mathcal{J}}{\partial B^{[l]}}$ 分别为函数 $\mathcal{J}$ 对变量 $W^{[l]}$ 和 $B^{[l]}$ 的偏导数。
我们只要给定了 $W^{[l]}$ 和 $B^{[l]}$ 的初值,确定了迭代步长,给出计算偏导数的方法,那么就可以迭代求得一个理想的参数最优解。
3.2 应用反向传播计算偏导数
实际应用中,$W^{[l]}$ 和 $B^{[l]}$ 的初值好确定,采用随机数即可(不可初始化为 $0$)。迭代步长可以通过经验确定。剩下的问题就是如何求解各个参数的偏导数了。
为了回答这个问题,我们把函数 $\hat{Y}=f\left(W^{[1]}, W^{[2]},…, W^{[L]}, B^{[1]}, B^{[2]},…, B^{[L]}, X \right)$ 的形式再具象化一些:
回顾一下在 2.2 节最后我们得出了神经网络各层输出值之间的关系,$Z^{[l]}=W^{[l]}A^{[l-1]} + B^{[l]}$,$A^{[l]}=g^{[l]}(Z^{[l]})$ 。对比该公式,我们可以发现在这里 $\hat{Y}$ 就是 $A^{[L]}$。进一步我们可以把上边的公式写成递归形式:
$A^{[0]}$ 就是 $X$。显然,我们可以应用函数的链式求导法则,一步步地求得从 $\mathcal{J}$ 对 $W^{[L]}$,$B^{[L]}$ 到对 $W^{[1]}$,$B^{[1]}$ 的偏导数。
这里边存在一个问题,当 $l=L$ 时,我们知道 $\mathcal{J}$ 关于 $\hat{Y}$ 也就是 $A^{[L]}$ 的具体形式(因为这个函数是我们构造出来的),可以很容易的求得其偏导数。当 $l<L$ 时,我们无法直接从 $\mathcal{J}$ 求出来。不过我们发现,$Z^{[l]}$ 是 $A^{[l-1]}$ 的函数。根据链式求导法则,可以得到
也就是说,我们可以通过 $\frac{\partial \mathcal{J}}{\partial A^{[L]}}$ 一层层的反向计算直到求得 $\frac{\partial \mathcal{J}}{\partial A^{[l]}}$。至此为止,梯度下降法求解过程中的各个环节都打通了。
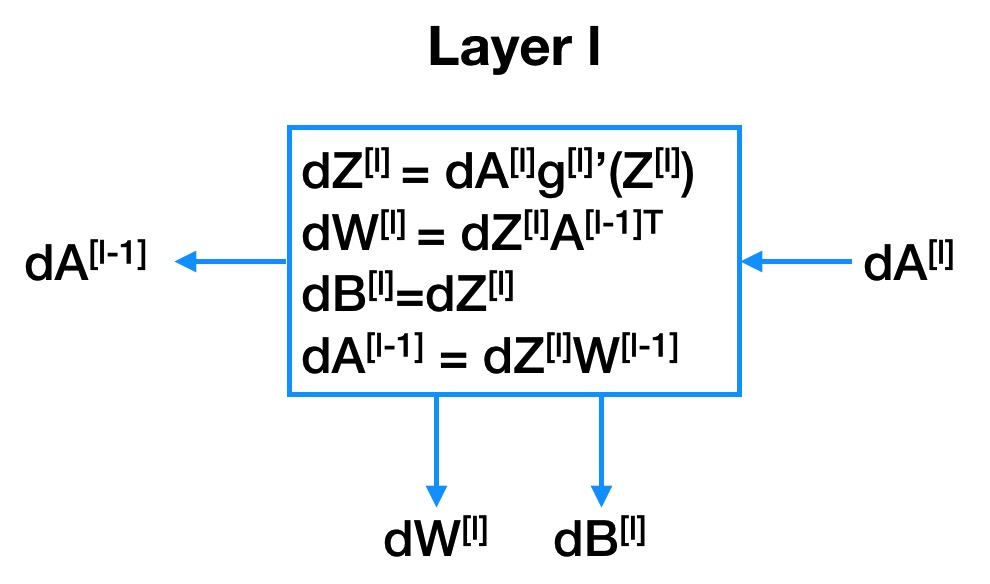
3.3 反向传播的图形化表示
需要说明一点的是,图中采用了符号简写,对于变量 $a$,$\frac{\partial \mathcal{J}}{\partial a}=\mathrm{d}a$,这也是在课程 deep learning 中的表达方式。
4. 如何构建一个完整的神经网络系统
结合前向传播与反向传播的结构图,最终我们形成了如下的一个完整的神经网络参数计算相关的结构图,如下:
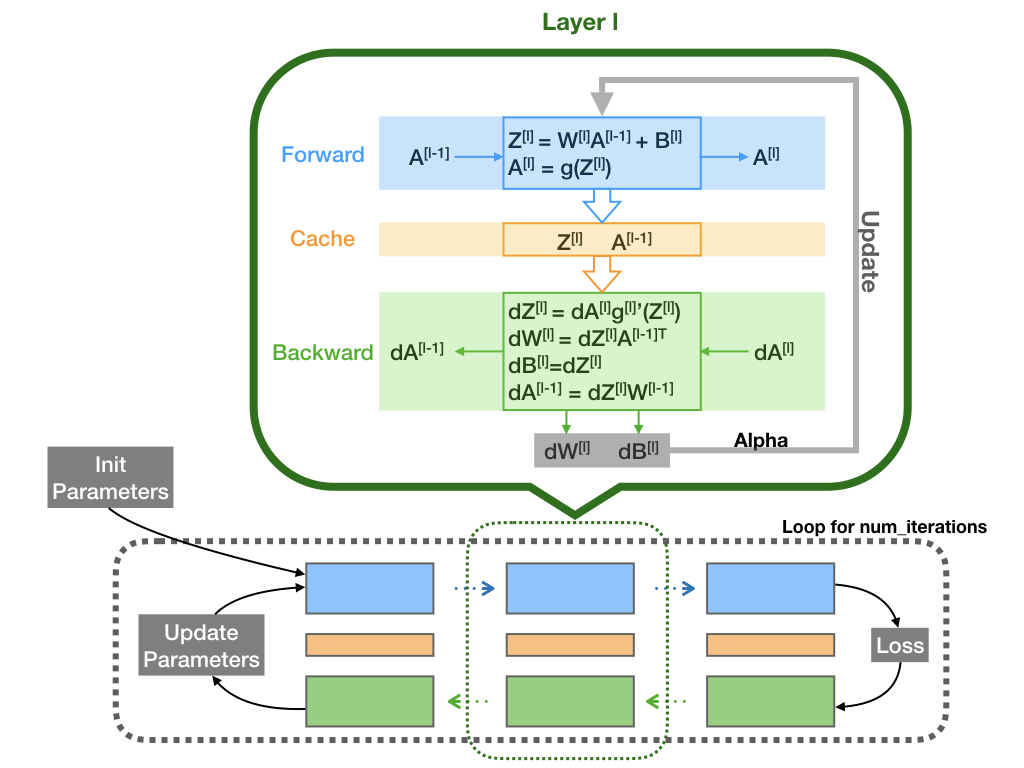
首先,我们需要先确定神经网络系统的大小尺寸,即需要构建的 Layer 数量,以及每个 Layer 中的 Node 数目。我们还需要确定在每一个 Layer 中选取的激活函数形式,一般来说,在最后一个 Layer 中都会选择 Sigmoid 函数作为激活函数。
其次,我们需要设定超参数 (Hyper parameters),比如说迭代次数,迭代步长等。
最后,随机初始化神经网络参数,输入训练集数据对参数进行最优化求解。在这一步中,每一次迭代中都要进行一次完整的前向传播计算以及反向传播计算。当迭代完成之后,就可以用训练好的参数对测试数据集进行验证了。
总结
神经网络是一种复杂的函数表现形式。
前向传播是神经网络对数据的预测过程。
反向传播是计算损失函数对神经网络这个函数中的不同层中参数的偏导数的过程。